
What’s in this article:
- ⌛The Problem; The bulk of time spent in a data science project is on the transformation of data itself.
- ⚰️The Classical Solution; using pandas to model complicated data for your analytics workflows isn’t the fastest way out.
- 💫The Revised Solution; Revisualizing the flow of data with dlt & Deepnote
- 🌍Clustering countries based on their wellness indicators
- 🔧Technical Conclusion; dlt & Deepnote are the data science dream team
- 🎆Analytical Conclusion; Leave women in dangerous situations for extended periods of time and they’ll begin to justify the violence committed against themselves!
⌛The Problem; The bulk of time spent in a data science project is on the transformation of data itself.
If you are a data analyst, data scientist or a machine learning engineer, then more likely than not, you spend more time fixing data pipelines or data formats then you do on ML algorithms or dashboard designs. We aren’t always lucky enough to get structured data to work with. Imagine a world where your training data is just this statement without no prior work:
select * from <dataset_table>
What a world that would be.
Unfortunately, before we get to writing this select statement, we need to go through
some very important but time consuming first steps. To describe what this journey looks
like, let’s list down the steps we usually undergo.
The usual flow of data for data science projects

We sign up for our jobs because we enjoy the last two activities the most. These parts have all the pretty charts, the flashy animations, and, if the stars align, include watching your hunches turn out to be statistically significant!
However, the journey to reach these stages is stretched much longer due to the time spent on data formats and pipelines. It would be such a load off my mind if they would get sorted themselves and we could skip to the good part. Sure, ipython notebooks with pandas and numpy help us in getting along, but what if there was something even simpler? Let’s explore different solutions.
A peak into the datasets 👀
The two datasets that we are using are nested json files, with further lists of dictionaries, and are survey results with wellness indicators for women. Here’s what the first element of one dataset looks like:
Looks like it is a nested json, nested further with more lists of dictionaries.
⚰️The Classical Solution; using pandas to model complicated data for your analytics workflows isn’t the fastest way out.
Usually, json_normalize can be used to unnest a json file while loading it into pandas. However, the nested lists inside dictionaries do not unravel quite well. Nonetheless, let’s see how the pandas normalizer works on our dataset.
Conclusion from looking at the data: pandas successfully flattened dictionaries but did not unnest lists. Perhaps because in order to unpack these lists, one might need to create new tables, essentially create a data model entirely. But, that is something pandas does not do for us. So, to be able to use it, let’s flatten the data further into arrays and tables. Particularly, let’s pay attention to the amount of code required to achieve this task.
To start off, using the pandas explode function might be a good way to flatten these lists:
And now, putting one of the nested variables into a pandas data frame:
And this little exercise needs to be repeated for each of the columns that we had to “explode” in the first place.
Our next step could be using a visualization package like matplotlib, and other pandas and numpy based functions to conduct a thorough exploratory analysis on the data. However, if we use the code above and plot two variables against each other on a scatter plot, for example, marriage_related and work_related, then joining this data wouldn’t be simple. We would have to be wary of the list indices (or something that can be used as foreign keys) that will match rows together across different tables. Otherwise, we would end up with mismatched data points on the scatter plot. We’ll get more into this in the Know your data model section.
💫The Revised Solution; Revisualizing the flow of data with dlt & Deepnote
We can reimagine the flow of data with dlt and Deepnote in the following way:
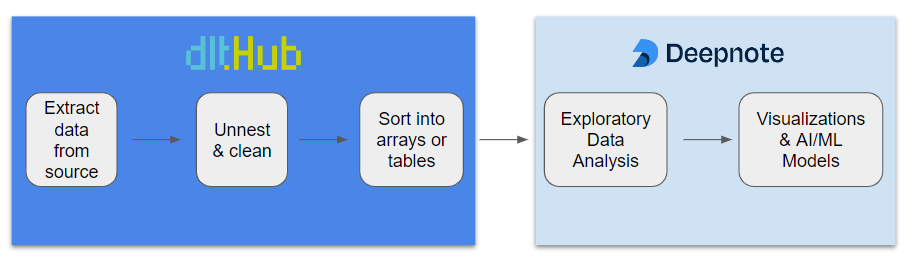
We leave the loading of the raw data to dlt, while we leave the data exploration and visualization to the Deepnote interface.
Introducing dlt; the data cleaner I wish I had
Imagine this: you initialize a data pipeline in one line of code, and pass complicated raw data in another to be modelled, unnested and formatted. Now, watch that come to reality:
And that’s pretty much it. Notice the difference in the effort you had to put in?
The data has been loaded into a pipeline with duckdb as its destination. duckdb was chosen as it is an OLAP database, perfect for usage in our analytics workflow. The data has been unnested and formatted. To explore what exactly was stored in that destination, a duckdb connector (conn) is set up, and the SHOW ALL TABLES command is executed.
In a first look, we understand that both the datasets violence and wellness have their own base tables. One of the child tables is shown below:
Know your data model; connect the unnested tables using dlt’s pre-assigned primary and foreign keys:
The child tables, like violence__value or wellness__age_related are the unnested lists of dictionaries from the original json files. The _dlt_id column as shown in the table above serves as a primary key. This will help us in connecting the children tables with ease. The parent_id column in the children tables serve as foreign keys to the base tables. If more then one child table needs to be joined together, we make use of the _dlt_list_idx column;
Deepnote - the iPython Notebook turned Dashboarding tool
Take your average Notebook experience, and combine it with the powers of a collaborative and interactive dashboarding tool and you get Deepnote. Now that we focus on analytics portion of this article, let’s check out how Deepnote helps along the way.
One step visualizations
At this point, we would probably move towards a plt.plot or plt.bar function. However, with Deepnote, the little Visualize button on top of any data frame will help us jump straight to an easy figure. Clicking on the Visualize button takes you to a new cell block, where you can choose your parameters, types of charts, and customization settings in the sidebar. The following chart is built from the joined data frame we defined above.
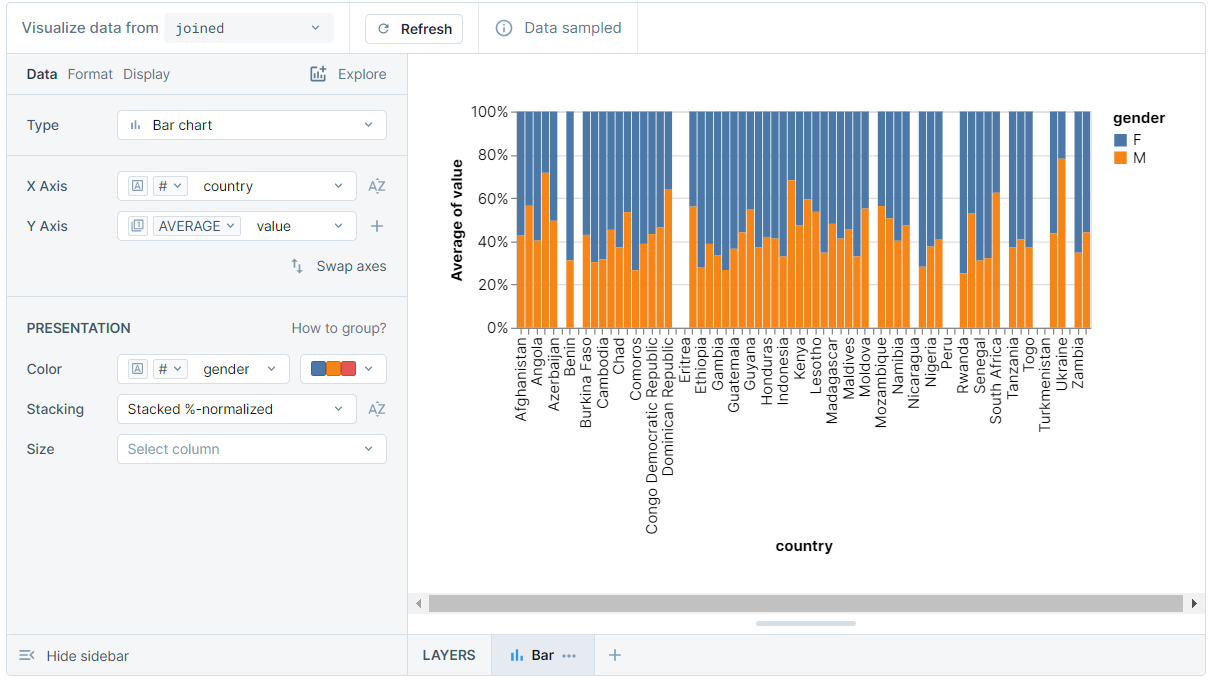
And a stacked bar chart came into existence! A little note about the query results; the value column corresponds to how much (in %) a person justifies violence against women. An interesting yet disturbing insight from the above plot: in many countries, women condone violence against women as often if not more often than men do!
The next figure slices the data further by gender and demographic. The normalized bar chart is sliced by 2 parameters, gender and demographic. The two colors represent genders. While different widths of the rectangles represent the different demographics, and the different heights represent that demographic’s justification of violence in %. The taller the rectangle, the greater the % average. It tells us that most women think that violence on them is justified for the reasons mentioned, as shown by the fact that the blue rectangles make up more than 50% of respondents who say ‘yes’ to each reason shown on the x-axis. If you hover over the blocks, you will see the gender and demographic represented in each differently sized rectangle, alongside that subset’s percentage of justification of violence.
Let’s examine the differences in women’s responses for two demographic types: employment vs education levels. We can see that the blue rectangles for “employed for cash” vs “employed for kind” don’t really vary in size. However, when we select “higher” vs “no education”, we see that the former is merely a speck when compared to the rectangles for the latter. This comparison between employment and education differences demonstrates that education plays a much larger role in likelihood to influence women’s levels of violence justification.
Let’s look at one last plot created by Deepnote for the other dataset with wellness indicators. The upward moving trend shows us that women are much less likely to have a final say on their health if they are less educated.
🌍 Clustering countries based on their wellness indicators
Lastly, based on these indicators of wellness and violence about women, let’s use KMEANS to cluster these countries to see how the algorithm groups which countries together. The intersection of the ‘countries’ columns in both datasets results in the availability of data for 45 countries. The columns used in this model indicate per country:
the average years of education for women
% of women who have a final say over their health matters
% of women who have control over their finances
% of women working
% of violence justification
Within these countries, the KMEANs algorithm converges to 4 clusters.
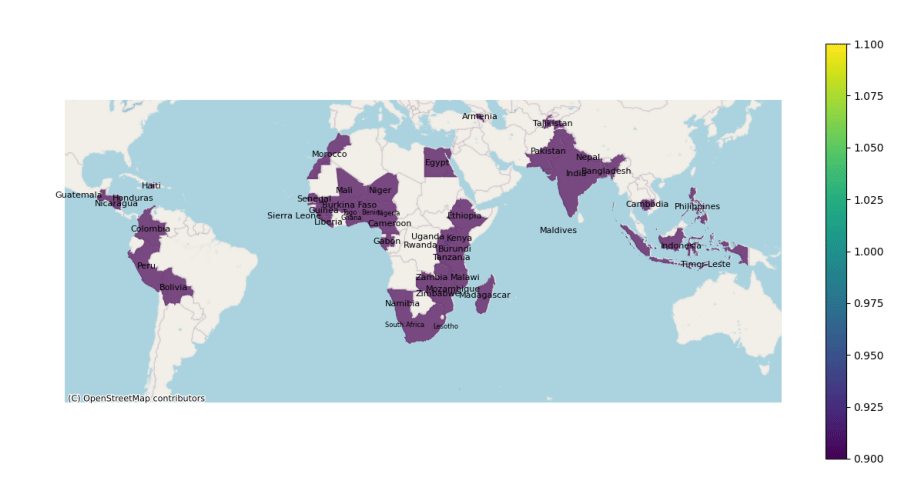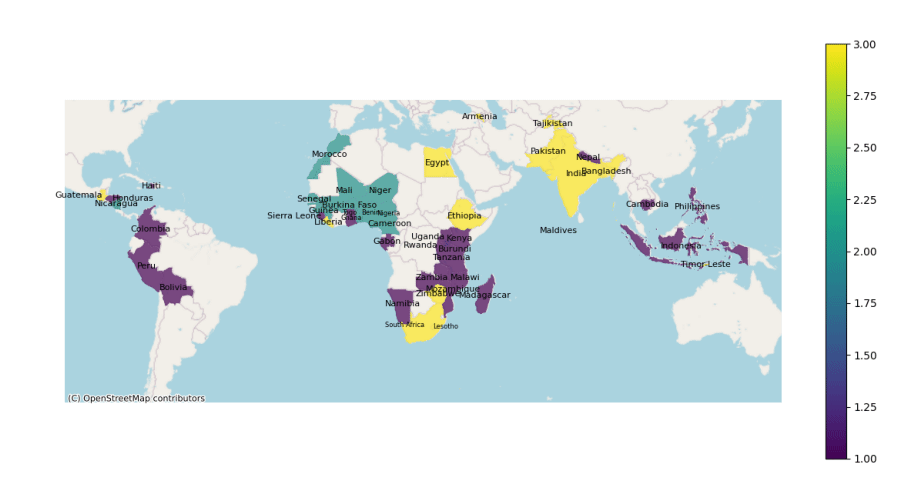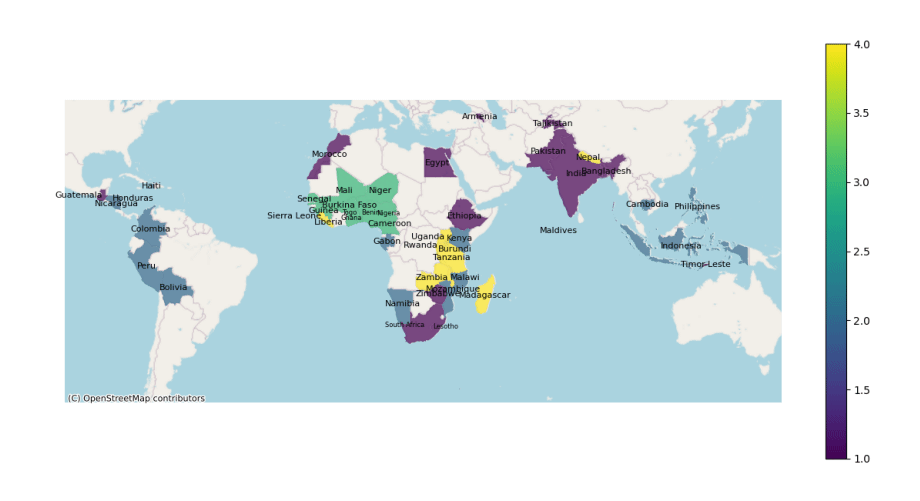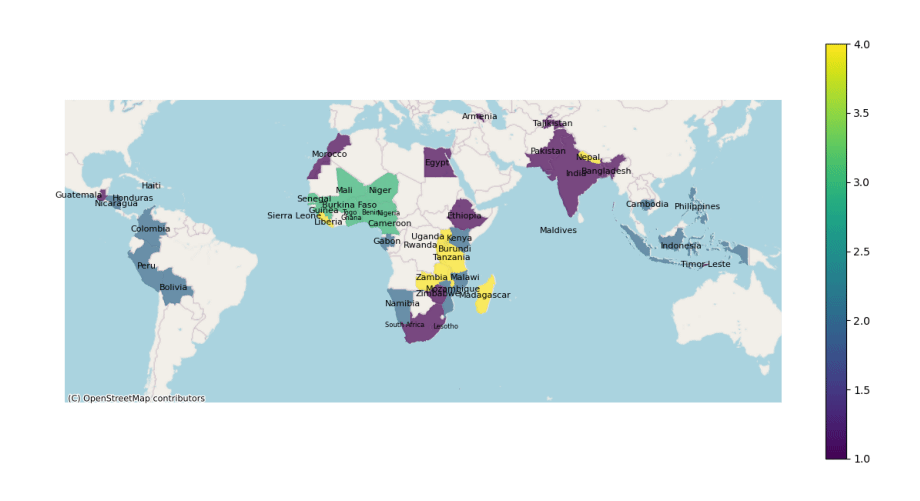
The color bar shows us which color is associated to which cluster. Namely; 1: purple, 2: blue, 3: green, and 4: yellow.
To understand briefly what each cluster represents, let’s look at the averages for each indicator across all clusters;
This tells us that according to these datasets, cluster 2 (highlighted blue) is the cluster that is performing the best in terms of wellness of women. It has the lowest levels of justifications of violence, highest average years of education, and almost the highest percentage of women who have control over their health and finances. This is followed by clusters 3, 1, and 4 respectively; countries like the Philippines, Peru, Mozambique, Indonesia and Bolivia are comparatively better than countries like South Africa, Egypt, Zambia, Guatemala & all South Asian countries, in regards to how they treat women.
🔧Technical Conclusion; dlt & Deepnote are the data science dream team
It is safe to say that dlt is a dream come true for all data scientists who do not want to 1. Wait for a data engineer to fix data pipeline issues and model discrepancies, or 2. Spend time studying the format of a dataset and find ways to structure and unnest it. The library supports many different sources and can pick up the dreadful data cleaning tasks you don’t want to do.
Next, let’s talk about the coding tool of choice for this article—Deepnote. With code blocks that come with AI code generation and debugging capabilities, and the built-in ability to use SQL on your Python DataFrame, you can quickly create multiple plots out of a given DataFrame. You can also easily slice your visualizations by various dimensions using Python-based visualization libraries like seaborn, matplotlib and plotly.
Using both of these tools together made the critical tasks of data loading and data exploration much easier for a data scientist or analyst by automating much of the upfront data preparation steps!
🎆Analytical Conclusion; Leave women in dangerous situations for extended periods of time and they’ll begin to justify the violence committed against themselves!
The data we explored in the plots above demonstrated that women often justify violent acts committed against themselves almost as equally as men do. Particularly, women who are less educated are more likely to fall into the shackles of these beliefs when compared to their more educated counterparts.
Additionally, the data also shows us women who are less educated have less input on the fate of their personal health. Thus, misogyny is often internalized and condoned by women themselves, especially by those who are less educated. It is not enough to be kinder toward women—we need to advocate for their education to be able to fight the sexism and prejudice that often start within women themselves.
P.S. If you want to explore this notebook on your own, then here’s the link to it!