In a recent article, Anna Geller, product manager at Kestra, highlighted why data ingestion will never be solved. In her article, she described the many obstacles around data ingestion, and detailed how various companies and open-source tools approached this problem.
I’m Adrian, data builder. Before starting dlthub, I was building data warehouses and teams for startups and corporations. Since I was such a power-builder, I have been looking for many years into how this space could be solved.
The conviction on which we started dlt is that, to solve the data ingestion problem, we need to identify the motivated problem solver and turbo charge them with the right tooling.
The current state of data ingestion: dependent on vendors or engineers.
When building a data pipeline, we can start from scratch, or we can look for existing solutions.
How can we build an ingestion pipeline?
- SaaS tools: We could use ready-made pipelines or use building blocks to configure a new API call.
- SDKs: We could ask a software developer to build a Singer or Airbyte source. Or we could learn object-oriented programming and the SDKs and become the software developer - but the latter is an unreasonable pathway for most.
- Custom pipelines: We could ask a data engineer to build custom pipelines. Unfortunately, everyone is building from scratch, so we usually end up reinventing the flat tire. Pipelines often break and have a high maintenance effort, bottlenecking the amount that can be built and maintained per data engineer.
Besides the persona-tool fit, in the current tooling, there is a major trade-off between complexity. For example, SaaS tools or SaaS SDKs offer “building blocks” and leave little room for customizations. On the other hand, custom pipelines enable one to do anything they could want but come with a high burden of code, complexity, and maintenance. And classic SDKs are simply too difficult for the majority of data people.
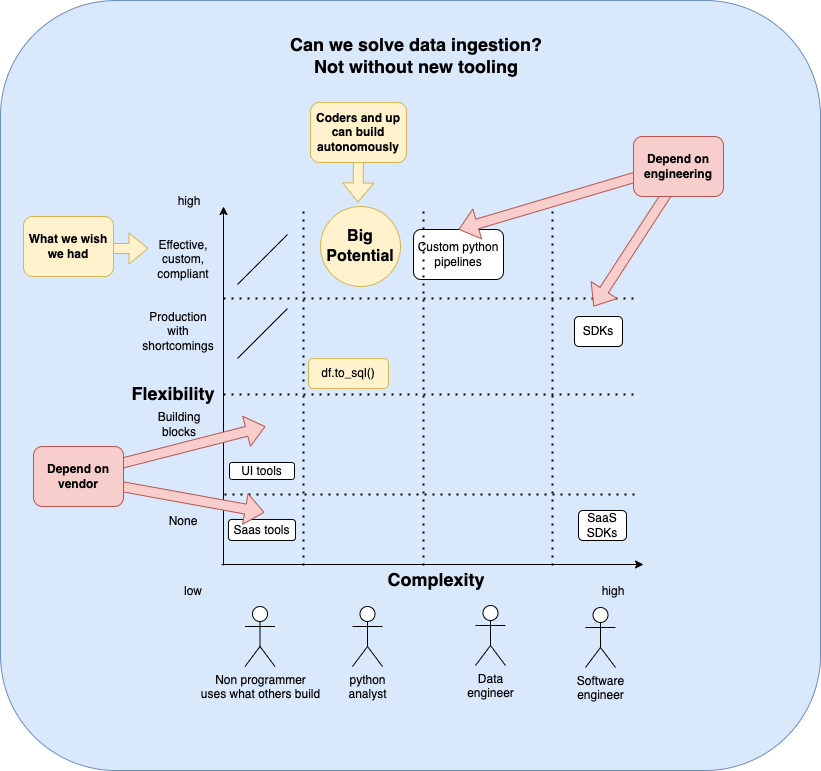
So how can we solve ingestion?
Ask first, who should solve ingestion. Afterwards, we can look into the right tools.
The builder persona should be invested in solving the problem, not into preserving it.
UI first? We already established that people dependent on a UI with building blocks are non-builders - they use what exists. They are part of the demand, not part of the solution.
SDK first? Further, having a community of software engineers for which the only reason to maintain pipelines is financial incentives also doesn’t work. For example, Singer has a large community of agencies that will help - for a price. But the open-source sources are not maintained, PRs are not accepted, etc. It’s just another indirect vendor community for whom the problem is desired.
The reasonable approach is to offer something to a person who wants to use the data but also has some capability to do something about it, and willingness to make an effort. So the problem has to be solved in code, and it logically follows that if we want the data person to use this without friction, it has to be Python.
So the existing tools are a dead end: What do custom pipeline builders do?
Unfortunately, the industry has very little standardization, but we can note some patterns.
df.to_sql() was a great first step
For the Python-first users, pandas df.to_sql() automated loading dataframes to SQL without having to worry about database-specific commands or APIs.
Unfortunately, this way of loading is limited and not very robust. There is no support for merge/upsert loading or for advanced configuration like performance hints. The automatic typing might sometimes also lead to issues over time with incremental loading.
Additionally, putting the data into a dataframe means loading it into memory, leading to limitations. So a data engineer considering how to create a boilerplate loading solution would not end up relying on this method because it would offer too little while taking away fine-grain control.
So while this method works well for quick and dirty work, it doesn’t work so well in production. And for a data engineer, this method adds little while taking away a lot. The good news: we can all use it; The bad news: it’s not engineering-ready.
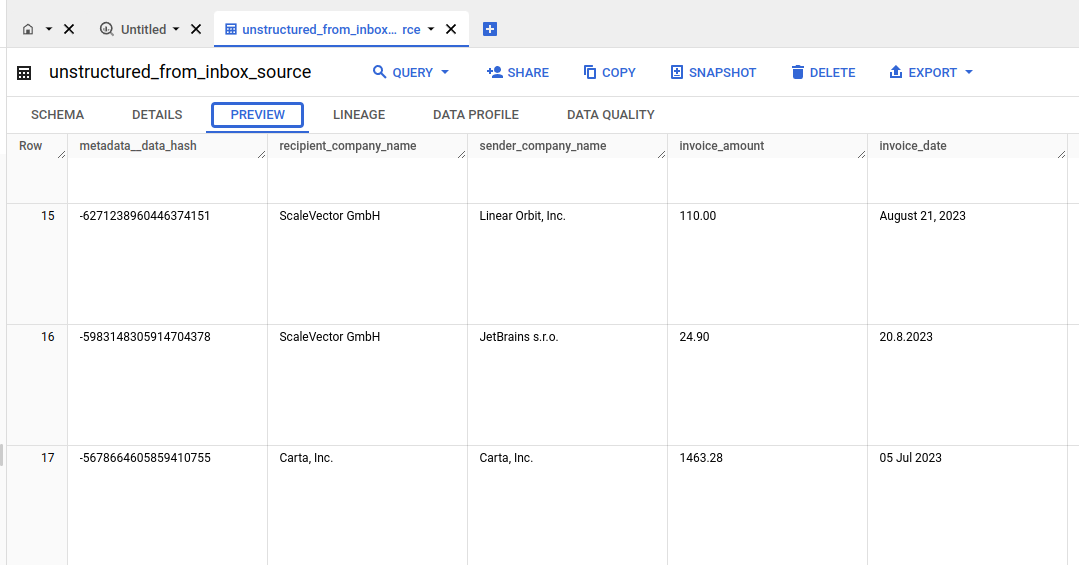
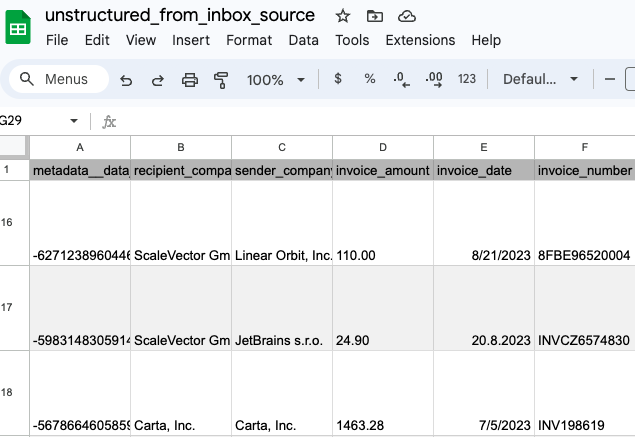
Inserting JSON directly is a common antipattern. However, many developers use it because it solves a real problem.
Inserting JSON “as is” is a common antipattern in data loading. We do it because it’s a quick fix for compatibility issues between untyped semi-structured data and strongly typed databases. This enables us to just feed raw data to the analyst who can sort through it and clean it and curate it, which in turn enables the data team to not get bottlenecked at the data engineer.
So, inserting JSON is not all bad. It solves some real problems, but it has some unpleasant side effects:
- Without an explicit schema, you do not know if there are schema changes in the data.
- Without an explicit schema, you don’t know if your JSON extract path is unique. Many applications output inconsistent types, for example, a dictionary for a single record or a list of dicts for multiple records, causing JSON path inconsistencies.
- Without an explicit schema, data discovery and exploration are harder, requiring more effort.
- Reading a JSON record in a database usually scans the entire record, multiplying cost or degrading performance significantly.
- Without types, you might incorrectly guess and suffer from frequent maintenance or incorrect parsing.
- Dashboarding tools usually cannot handle nested data - but they often have options to model tabular data.
Boilerplate code vs one-offs
Companies who have the capacity will generally create some kind of common, boilerplate methods that enable their team to re-use the same glue code. This has major advantages but also disadvantages: building something like this in-house is hard, and the result is often a major cause of frustration for the users. What we usually see implemented is a solution to a problem, but is usually immature to be a nice technology and far from being a good product that people can use.
One-offs have their advantage: they are easy to create and can generally take a shortened path to loading data. However, as soon as you have more of them, you will want to have a single point of maintenance as above.
The solution: A pipeline-building dev tool for the Python layman
Let’s let Drake recap for us:

So what does our desired solution look like?
- Usable by any Python user in any Python environment, like df.to_sql()
- Automate difficult things: Normalize JSON into relational tables automatically. Alert schema changes or contract violations. Add robustness, scaling.
- Keep code low: Declarative hints are better than imperative spaghetti.
- Enable fine-grained control: Builders should be enabled to control finer aspects such as performance, cost, compliance.
- Community: Builders should be enabled to share content that they create
We formulated our product principles and went from there.
And how far did we get?
- dlt is usable by any Python user and has a very shallow learning curve.
- dlt runs where Python runs: Cloud functions, notebooks, etc.
- Automate difficult things: Dlt’s schema automations and extraction helpers do 80% of the pipeline work.
- Keep code low: by automating a large chunk and offering declarative configuration, dlt keeps code as short as it can be.
- Fine-grained control: Engineers with advanced requirements can easily fulfill them by using building blocks or custom code.
- Community: We have a sharing mechanism (add a source to dlt’s sources) but it’s too complex for the target audience. There is a trade-off between the quality of code and strictness of requirements which we will continue exploring. We are also considering how LLMs can be used to assist with code quality and pipeline generation in the future.
What about automating the builder further?
LLMs are changing the world. They are particularly well-suited at language tasks. Here, a library shines over any other tool - simple code like you would write with dlt can automatically be written by GPT.
The same cannot be said for SDK code or UI tools: because they use abstractions like classes or configurations, they deviate much further from natural language, significantly increasing the complexity of using LLMs to generate for them.
LLMs aside, technology is advancing faster than our ability to build better interfaces - and a UI builder has been for years an obsolete choice. With the advent of self-documenting APIs following OpenAPI standard, there is no more need for a human to use a UI to compose building blocks - the entire code can be generated even without LLM assistance (demo of how we do it). An LLM could then possibly improve it from there. And if the APIs do not follow the standard, the building blocks of a UI builder are even less useful, while an LLM could read the docs and brute-force solutions.
So, will data ingestion ever be a fully solved problem? Yes, by you and us together.
In summary, data ingestion is a complex challenge that has seen various attempts at solutions, from SDKs to custom pipelines. The landscape is marked by trade-offs, with existing tools often lacking the perfect balance between simplicity and flexibility.
dlt, as a pipeline-building dev tool designed for Python users, aims to bridge this gap by offering an approachable, yet powerful solution. It enables users to automate complex tasks, keep their code concise, and maintain fine-grained control over their data pipelines. The community aspect is also a crucial part of the dlt vision, allowing builders to share their content and insights.
The journey toward solving data ingestion challenges is not just possible; it's promising, and it's one that data professionals together with dlt are uniquely equipped to undertake.
Resources:
- Join the ⭐Slack Community⭐ for discussion and help!
- Dive into our Getting Started.
- Star us on GitHub!








 DeepAI Image with prompt: People stuck with tables.
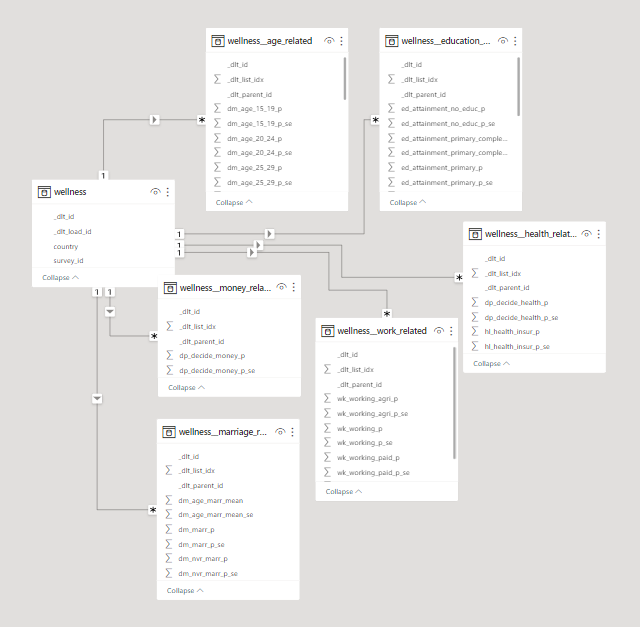
DeepAI Image with prompt: People stuck with tables.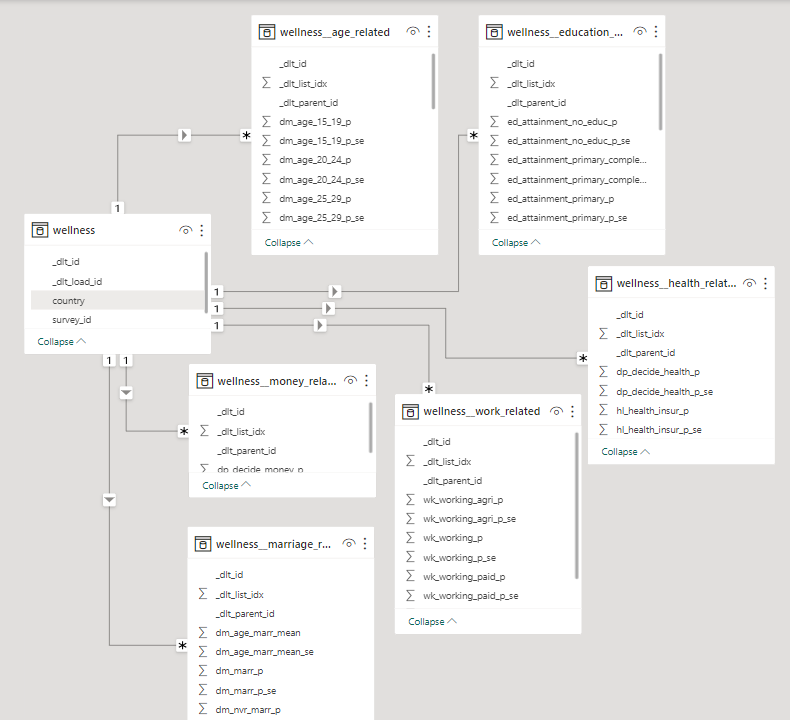 The database schema as presented by a Power BI Model.
The database schema as presented by a Power BI Model.